- Smoke Signals: Navigating the Evolving Landscape of Nicotine and Tobacco Regulations
- Posts
- Introduction - Smoke Signals: Navigating the Evolving Landscape of Nicotine and Tobacco Regulations
Introduction - Smoke Signals: Navigating the Evolving Landscape of Nicotine and Tobacco Regulations
Using Generative AI to Analyze FDA CTP Reviewer Documents and Introductions in 2024
Jon Dice
January 22, 2024
# 01
Welcome in 2024. Many thanks for signing up to the Smoke Signals Newsletter. Since some of you didn’t get my welcome email when you signed up, here goes again. My name is Jon Dice and I’ve had this idea to bridge a connection with tobacco and nicotine industry professionals for many years. I now have the opportunity to share some of my insights in this newsletter format. I’ve done weekly and monthly trade press and literature review newsletters in the past but I think with this newsletter I’d like to go deeper into more regulatory and scientific affairs-related content as I see the opportunities. I also post more breaking-news type content with any initial thoughts on LinkedIn which is where everybody seems to be these days.
My goal is to provide value to those in the industry doing the important work of harm reduction by collecting information from a variety of sources and providing actionable insights from my 20 years of industry experience. Over time I’d like to dive deeper into topics as they evolve and this newsletter provides a platform to analyze industry issues as they develop. Much of what we experience is reactive. I’d like to try to get ahead of issues and be more proactive in anticipation of FDA CTP decisions and marketplace shifts in the US and abroad.
Topics of Potential Interest in the Future
PMTA strategy formulation
MDO litigation tracking
Analyzing CTP’s policy agenda
Important ENDS publications discussions
Regulatory Intelligence: Offering access to a comprehensive regulatory intelligence database, featuring thousands of PMTA, MRTPA, and SE applications, as well as FDA CTP reviewer documents. I’m building this out and it’s a massive amount of work so I’m not sure when it will be available.
Leveraging artificial intelligence (AI) in the nicotine and tobacco industry
Edit: So it just so happens that I have been working on a piece about artificial intelligence since it is everywhere, all the time and I see enormous potential for it to help our industry with the proper setup and guardrails. So here goes from a non-expert perspective…
Using Generative AI to Analyze FDA CTP Reviewer Documents
Generative AI image - the extra finger phenomenon
There is immense potential in the area of generative artificial intelligence (AI) to assist in the document analysis of large data sets. As a proof-of-concept I combined the Substantial Equivalence (SE) Final Rule document with several SE reviewer guides and scientific policy memoranda related generally to FDA review of tobacco product applications and specifically to SE Reports. I used this data set because the SE review process at CTP is more mature and there is more information publicly available to analyze. There have also been many more market authorizations for SE so the training data should theoretically be more "trainable". After cleaning up the combined document by removing redacted pages and OCR'ing certain text elements I used petal.org's document analysis platform (free version) to upload, extract and process the ~455 page document (1.3M characters). From my current (and limited) understanding this involves a process called "chunking" which is a technique used to organize and process information efficiently.
At this point there are so many new AI and natural language processing (NLP - a subfield of AI) software technologies and techniques being developed almost weekly (both open-source and proprietary) that it's basically impossible to keep track of it all. My focus for this exercise was to leverage currently available technology to do a job and in this case it is to quickly analyze a large public data set to answer specific questions about SE so I don't have to spend time repeatedly reading reviewer guides, reference documents and final rules when in the process of doing work. I was in the SE trenches for many years and would’ve greatly appreciated a tool like this.
To be sure this technology goes way beyond CTRL+F search for keywords in documents and I'm consistently impressed with the output it generates, but information is not knowledge. That being said, there is an art and a science to asking the correct questions (prompts) to get the information you want and it does require a substantial amount of background knowledge to use the tools effectively and confirm that the data is generally correct. I curated a list of 10 prompts for this document analysis which I've listed below. To quantify the time savings, this 10-question prompt sequence may have taken me an hour to complete by reading the documents and typing responses at the same quality and depth of content. This entire prompt-response sequence using this tool took probably less than 5 minutes in total. As noted this was a proof-of-concept exercise, kind of like conversing with the document via chatbot, so I created prompts that were general enough to provide relevant information for someone new to the data. This type of document could be used as a new-hire onboarding document, regulatory subject matter expert reference or a glossary of terms for an application.
I was concerned about repeatability of output so I input the same prompts in different sessions. The responses did not seem to change much. Probably because this was a simple document analysis more related to NLP and not taking into account broader AI models (OpenAI probably being the most well-known) which are becoming more familiar but still a bit hallucinatory. Building quality data models requires good curation and computing power. Future direction will include better extraction methods for data tables from pdfs (HPHC and ingredient data for SE and PMTA) as well as running local large language models (LLM) for more precision and better data security around proprietary information.
Prompts:
Explain the substantial equivalence process.
Provide information related to how a toxicology reviewer assesses an application. What are the most important considerations?
Provide an overview of the information used to support social science review of SE Reports.
Provide a summary of the review used to support behavioral and clinical pharmacology for SE Reports.
Explain equivalence testing for SE Reports.
What is a surrogate tobacco product?
Provide an overview of stability testing for smokeless tobacco products.
Is clinical data needed in order to review a SE Report?
Explain what a different question of public health means.
What are 2 of the deficiencies most commonly seen in SE Reports?

Click on the image to see the 10-prompt sequence report
➢ENDS PMTA Marketing Denial Order Litigation Appeals Tracker (non-exhaustive)
This is an ever-evolving list of appeals, with the most recent (as of this publishing) being the Shenzhen IVPS Technology Co., Ltd., (SMOK brand) appeal in the 5th Circuit Court of Appeals on January 19, 2024. I try to track this but it’s definitely not my specialty.
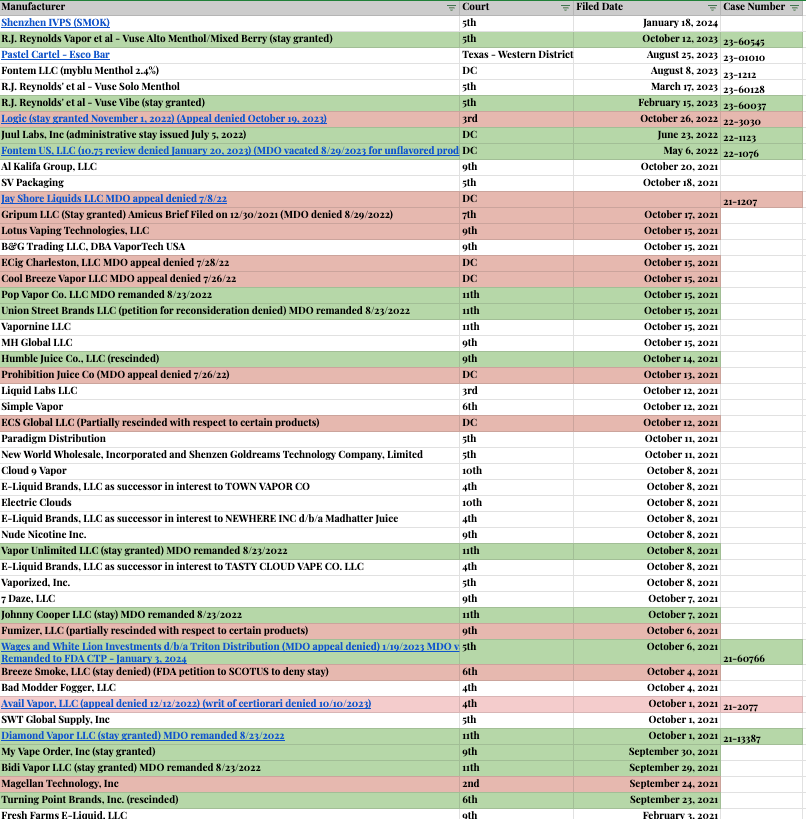
Green indicates a generally favorable ruling (so far) and red is a negative ruling.
For the beginning of 2024, I’m spending time collecting information to build out a tobacco, nicotine and harm reduction knowledge base. This includes gathering technical project lead (TPL) memos, Tobacco Product Scientific Advisory Committee (TPSAC) material and any other regulatory and scientific affairs collateral that may be helpful as FDA CTP moves into the next phase of their 5-year strategic plan. I’m also working on developing a periodic publication review of relevant literature in the nicotine and harm reduction space with some help from friends.
Thanks for following along. Times are incredibly difficult in the industry but if you’re not in the game you have no chance of winning so I continue moving forward and control what I can.
Cheers
Jon